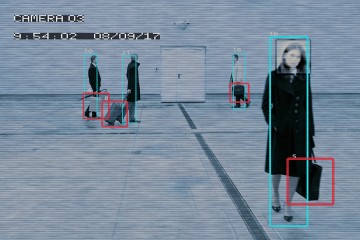
Imagine standing on the sidewalk of a busy city street, taking in your surroundings. "When you or I look at that scene, we have a task in mind—whether to find a place to eat or shop, the metro station, or a particular person," says René Vidal, a Johns Hopkins professor of biomedical engineering. We take into account variables such as lighting, weather, and our angle of view. We're able to distinguish the guy walking his dog from the suspicious one who seems to be following us. We can tell a car that's pulling into a parking spot from one about to smash into a building.
For all that computers can do better than humans—from playing the stock markets to figuring out the band behind that song stuck in our head—we still have them beat in at least one important way. "We can filter out information that isn't relevant, or note information that is out of the ordinary," Vidal says. "Our question is: How can we get computers to do the same?"
Computers can already process massive amounts of data. Vidal's team is trying to program them to process semantic information—the meaning and relationships among people, objects, environments, and actions. This could help defense and law enforcement agencies quickly figure out what happened in the aftermath of an act of terrorism, and possibly even prevent it from happening in the first place. If computers could simultaneously analyze the contexts and relationships of photographs, videos, audio, text documents, and internet activity—collectively known as "multimodal data"—they could become digital detectives, with faster, more accurate, and greater processing abilities than humans.
That's why the U.S. Department of Defense issued a call for white papers through its Multidisciplinary University Research Initiative program. In response, Vidal assembled an all-star team of researchers, and in 2017 their proposal won the five-year, $11 million grant for a project called the Semantic Information Pursuit for Multimodal Data Analysis, funded jointly by the Department of Defense and the U.K.'s Engineering and Physical Sciences Research Council.
As the project's principal investigator and director of the Johns Hopkins Mathematical Institute for Data Science, Vidal is tackling one of its core functions: computer vision. In humans, our vision feeds information to the databases of our brains, helping us interpret the world around us. In order for computers to do the same, they must be able to recognize and categorize objects, distinguishing a body from a building, a truck from a gun. And they must be able to do so from multiple angles and in multiple shades of light. They must also be able to recognize "deformable" objects such as smoke or water, or even the many expressions of a human face. They must produce a three-dimensional interpretation of an object based on a camera's two-dimensional view, and then track its movement through space and time.
Once objects in the scene are identified, they must be analyzed in terms of placement and relationship to one another. This ability, called "parsing," is being pursued by Donald Geman, a Johns Hopkins professor of applied mathematics and statistics and Vidal's colleague at the Johns Hopkins Center for Imaging Science. There, Geman is developing a strategy for computers to understand what's going on in a given scene using techniques similar to how we reason through a game of 20 Questions. "But for a computer," Vidal explains, "it's more like 20,000 questions at a very rapid pace. It might begin with, 'Is that a person in the top right? Is that a street in the middle?'" Each answer informs the nature and direction of subsequent questions. Geman aims to apply this principle to computer capabilities that can quickly shift from one scene to another, or zoom from a broad view to a specific point of focus. Parsing is necessary to the computer's next step of determining extraordinary or dangerous circumstances, which, of course, is essential to the Defense Department's objective.
The other eight members of the Semantic Information Pursuit team bring expertise in fields ranging from machine learning to mathematical optimization, predictive statistics, and quantum computing. They represent Stanford University; the University of Maryland; the University of California, Berkeley; the University of Southern California; the University of California, Los Angeles; Oxford University; University of Surrey; and University College London.
If successful, Vidal says, the model that his team develops could be adapted for purposes well beyond security. Computers could take in medical data—MRI scans, blood tests, and so on—and make a diagnosis faster and more accurately than a human alone. Or it could help an autonomous vehicle distinguish objects like mailboxes or bus stops that won't alter its course from those that may, such as other cars, bicycles, or pedestrians.
The ideas behind Semantic Information Pursuit may sound far-fetched and futuristic, but Vidal reminds us how rapidly technology can advance. "Think about voice recognition software," he says. "Five years ago, many users joked about the shortcomings of Apple's Siri. But today, similar applications such as Amazon's Alexa have set new standards and new potential. As machine learning advances, so will our ability to help computers understand and interpret the contexts of data."
Posted in Politics+Society